P1-rapporten forklaret — Fra rotationskurver til svag gravitationslinsevirkning: test af EFT’s gennemsnitlige gravitationsrespons
En offentlig formidling baseret på P1_RC_GGL: En streng lukningstest af galaksedynamik og svag gravitationslinsevirkning (v1.1)
Læs den oprindelige evalueringsrapport:
1. ChatGPT: https://chatgpt.com/share/6a00cd62-6e34-83eb-b165-6ec09e3519cc
2. Gemini: https://gemini.google.com/share/773ec96d75a0
3. Grok: https://grok.com/share/bGVnYWN5LWNvcHk_c0b4fa65-0e86-4adb-9b58-5617d616dc04
4. Qwen: https://chat.qwen.ai/s/22ab9336-671f-420a-a7fa-43e24774bb2a?fev=0.2.46
5. DeepSeek: https://chat.deepseek.com/share/tj6k7hb5owtoldg2bm
Læsebemærkning |
Dette er en forklarende version, ikke en separat akademisk rapport. Den bygger på den oprindelige P1-rapport, bevarer de centrale figurer og tabeller og tilføjer forklaringer i almindeligt sprog af, hvad hvert vigtigt trin betyder. |
Denne guide forklarer kun, hvad P1 konkluderer under sine specificerede datasæt, parameterregnskab og statistiske protokol: I den fælles test af galaksers rotationskurver (RC) og svag galakse–galakse-linsevirkning (GGL) klarer EFT’s model for gennemsnitlig gravitationsrespons sig klart bedre end den minimale DM_RAZOR-baseline, der testes her. |
Denne guide fortolker ikke P1 som en påstand om, at »mørkt stof er væltet«. P1 er kun første trin i P-seriens eksperimenter. Den tester ét observerbart lag af EFT — den »gennemsnitlige gravitationsbund« — ikke hele indholdet af den komplette EFT-ramme. |
0 | Forstå P1 på fem minutter: Hvad gør denne test?
Tænk på P1 som en konsistenstest på tværs af sonder. Den spørger ikke blot, om en model kan tilpasse ét datasæt. I stedet lægger den to meget forskellige gravitationsaflæsninger på samme auditbænk: rotationskurver (RC) aflæser dynamikken inde i galakseskiver, mens svag galakse–galakse-linsevirkning (GGL) aflæser den projicerede gravitationsrespons på større skalaer.
- RC er som et speedometer: den fortæller, hvor hurtigt gas og stjerner roterer ved forskellige radier i en galakseskive.
- GGL er som en vægt: ved at måle, hvordan forgrundsgalakser svagt bøjer lyset fra baggrundsgalakser, udleder den den gennemsnitlige gravitations-/massefordeling omkring galakser på større skalaer.
- P1’s centrale spørgsmål er dette: Kan den samme model først lære et mønster fra RC, derefter overføre dette mønster til GGL og stadig give mening?
P1 i én sætning |
P1 hæver barren fra »passer den én sonde godt?« til »lukker den på tværs af sonder?« En model har sandsynligere fanget en gravitationsstruktur, som RC og GGL deler, kun hvis den klarer sig godt under den korrekte mapping, og signalet kollapser efter at mappingen er shuffled. |
Tabel 0 | P1’s kernetal og hvordan de læses
Måleparameter | Læsning i P1 / P1A | Betydning i almindeligt sprog |
Joint-fit ΔlogL_total | I hovedtekstsammenligningen ligger EFT 1155–1337 over DM_RAZOR | Totalscoreforskellen på tværs af de to datasæt; større betyder en bedre samlet forklaring. |
Lukningsstyrke ΔlogL_closure | I hovedtekstsammenligningen er EFT 172–281, mens DM_RAZOR er 127 | Evnen til at forudsige GGL efter inferens fra RC alene; større betyder stærkere selvkonsistens på tværs af sonder. |
Negativ-kontrol-shuffle | Efter shuffling af RC-bin→GGL-bin falder EFT’s lukningssignal til 6–23 | Hvis den korrekte korrespondance brydes, bør fordelen forsvinde; jo skarpere kollapset er, desto bedre udelukker det et falsk signal. |
P1A-stresstest med flere DM-varianter | DM 7+1 + DM_STD, med EFT_BIN bevaret som sammenligning | P1A ser ikke kun på den minimale DM_RAZOR-baseline. Den placerer flere lavdimensionelle, auditérbare DM-forbedringsgrene i den samme lukningsprotokol. |
1 | Hvorfor lave P1? Hvor sidder kosmologien på galakseskala fast?
Problemer på galakseskala har været vanskelige, fordi »behovet for ekstra gravitation/masse« ikke blot er et rotationskurvefænomen. Mange observationer viser en tæt forbindelse mellem synligt baryonisk stof i galakser og de faktiske dynamiske/linsningsmæssige aflæsninger. For ruten med mørkt stof betyder det, at mørke haloer, baryonisk feedback, galaksedannelseshistorie og observationelle systematikker skal koordineres med stor præcision. For gravitationsruter uden mørkt stof betyder det, at en model ikke blot kan se god ud på RC; den skal også overleve svag linsevirkning, populationsskaleringsrelationer og negative kontroller.
Det er motivationen for P1. Den begynder ikke med »mørkt stof er forkert« eller »EFT må være rigtig«. Den bringer én testbar påstand ind til audit: Kan EFT’s gennemsnitlige gravitationsrespons efterlade et reproducerbart og overførbart signal i RC→GGL-lukning på tværs af sonder?
Ekstern litteraturkontekst: Hvorfor RC+GGL-vinduet betyder noget |
Den radiale accelerationsrelation (RAR), foreslået af McGaugh, Lelli og Schombert i 2016, viser en tæt korrelation med lav spredning mellem den observerede acceleration sporet af rotationskurver og den acceleration, der forudsiges ud fra baryonisk stof. Det gør »baryon–gravitationsrespons-kobling« uomgængelig for teori på galakseskala. |
Brouwer et al. (2021) brugte KiDS-1000 svag linsevirkning til at udvide RAR til lavere accelerationer og større radier og sammenlignede MOND, Verlindes emergente gravitation og LambdaCDM-modeller. De bemærkede også, at forskelle mellem tidlige og sene galaksetyper, gashaloer og galakse–halo-forbindelsen fortsat er centrale forklaringsproblemer. |
Mistele et al. (2024) brugte yderligere svag linsevirkning til at udlede cirkulærhastighedskurver for isolerede galakser og rapporterede ingen tydelig nedgang ud til flere hundrede kpc og endda omtrent 1 Mpc, i overensstemmelse med BTFR. Det viser, at svag linsevirkning er ved at blive en vigtig ekstern aflæsning til test af gravitationsrespons på galakseskala. |
Derfor ligger P1’s værdi ikke i, at den er »den første til at diskutere RC og GGL sammen«. Værdien ligger i, at den placerer dem i en auditérbar protokol bygget på en fast mapping, et parameterregnskab, RC-only→GGL-lukning, shuffle-baserede negative kontroller og P1A-stresstests med flere DM-varianter.
2 | Hvad betyder EFT i P1? Det er ikke Effective Field Theory
Her henviser EFT til Energi-tråd-teori (Energy Filament Theory, EFT), ikke til den Effective Field Theory, som ofte bruges i fysik. I den tekniske P1-rapport bruges EFT med tilbageholdenhed: Den deltager ikke i sammenligningen som en komplet endelig teori, men komprimeres først til en observerbar, fit-klar og falsificerbar parameterisering af »gennemsnitlig gravitationsrespons«.
Sagt i almindeligt sprog begynder P1 ikke med at diskutere alle mikroskopiske kilder til ekstra gravitation, og den forsøger heller ikke at bevise hele EFT-rammen på én gang. Den stiller et snævrere og hårdere spørgsmål: Hvis der findes en form for gennemsnitlig ekstra gravitationsrespons på galakseskalaer, kan den så først forklare RC og derefter overføres til at forudsige GGL?
Hvilken del af EFT tester P1? |
P1 retter sig mod den »gennemsnitlige gravitationsbund«: et statistisk stabilt middelbidrag, der kan overføres på tværs af samples. |
P1 håndterer endnu ikke den »stokastiske/støj-bund«: de tilfældige led, individuelle forskelle eller ekstra spredning, som mere mikroskopiske fluktuationsprocesser kan indføre. |
P1 behandler heller ikke den komplette mikroskopiske mekanisme, forekomst, levetid eller globale kosmologiske begrænsninger. Den er første trin i P-seriens eksperimenter, ikke en endelig dom. |
3 | Planen for P1-serien: Hvorfor starte med »middelbunden«?
P-serien kan forstås som EFT’s observationsbaserede genfindingsprogram. Den lægger ikke alle påstande frem på én gang; i stedet isolerer den først den del, der lettest kan testes med offentlige data. P1’s strategi er at teste middelleddet først: Hvis gennemsnitlig gravitationsrespons ikke engang kan lukkes fra RC til GGL, mangler der et ordentligt indgangspunkt til at diskutere mere komplekse støjled eller mikroskopiske mekanismer.
Tabel 1 | P-seriens lagdelte placering
Lag | Spørgsmål | Rolle i P1 |
P1 | Kan gennemsnitlig gravitationsrespons lukke i RC→GGL? | Hovedspørgsmålet i den aktuelle rapport |
P1A | Hvis DM-siden styrkes, forbliver konklusionen så stabil? | Appendiks B: DM 7+1 + DM_STD-stresstest |
Senere P-serie-arbejde | Kan protokollen udvides til flere data, flere sonder og mere komplekse systematikker? | Retning for fremtidigt arbejde |
Spørgsmål på dybere niveau | Hvordan forbindes middelleddet, støjleddet og den mikroskopiske mekanisme? | Uden for P1’s konklusionsområde |
4 | Hvad er dataene? Hvad fortæller RC og GGL os?
4.1 Rotationskurver (RC): »hastighedsmåleren« inde i galakseskiver
Rotationskurver registrerer, hvor hurtigt gas og stjerner kredser om en galakses centrum ved forskellige radier. Jo hurtigere rotationen er, desto stærkere centripetalkraft kræves ved den radius — og dermed desto stærkere er den effektive gravitation. P1 bruger SPARC-databasen, med forbehandling der omfatter 104 galakser og 2.295 hastighedsdatapunkter, opdelt i 20 RC-bins.
4.2 Svag linsevirkning (GGL): En »gravitationsvægt« på større skala
Svag galakse–galakse-linsevirkning måler, hvordan forgrundsgalakser svagt bøjer lyset fra baggrundsgalakser. Den svarer til projiceret gravitationsrespons på større radier i halo-skala og afhænger ikke af detaljerne i gasdynamikken inde i en galakse. P1 bruger de offentlige GGL-data fra KiDS-1000 / Brouwer et al. (2021): 4 stjernemasse-bins, 15 radiale punkter pr. bin, i alt 60 datapunkter, med fuld kovarians anvendt.
4.3 Fast mapping: Hvorfor 20 RC-bins → 4 GGL-bins betyder noget
P1 forbinder de 20 RC-bins med de 4 GGL-bins gennem en fast regel: Hver GGL-bin svarer til 5 RC-bins, kombineret ved gennemsnit vægtet efter galaksetal. Denne mapping holdes uændret for alle modeller og fungerer som en hård begrænsning for lukningstest og fair sammenligning.
Hvorfor ikke tune mappingen bagefter? |
Hvis man bagefter kunne vælge, »hvilke RC-bins der svarer til hvilke GGL-bins«, kunne en model fremstille lukning ved at omarrangere korrespondancen. P1 låser 20→4-mappingen på forhånd og bryder den bevidst med en shuffle-negativ kontrol netop for at bedømme, om lukningssignalet virkelig afhænger af en fysisk rimelig korrespondance. |
5 | Modeller og metoder: Hvad sammenligner P1 præcist?
5.1 EFT-siden: Lavdimensionel gennemsnitlig gravitationsrespons
På EFT-siden bruges et lavdimensionelt ekstrahastighedsled til at beskrive gennemsnitlig gravitationsrespons. Formen på det ekstra led styres af en dimensionsløs kernefunktion f(r/ℓ), hvor ℓ er den globale skala, og amplituden tildeles pr. RC-bin. Forskellige kerner repræsenterer forskellige begyndelseshældninger, overgangshastigheder og langtrækkende haler og bruges til robustheds-stresstests.
5.2 DM-siden: Hovedtekstsammenligningen og appendiks P1A skal læses hver for sig
I hovedtekstsammenligningen er DM_RAZOR en minimeret, auditérbar NFW-baseline: Den bruger en fast c–M-relation og inkluderer ikke halo-til-halo-spredning, adiabatisk kontraktion, feedback-kerner, ikke-sfæricitet eller miljøled. Styrken ved dette design er kontrollerede frihedsgrader og let reproducerbarhed; svagheden er, at det ikke kan repræsentere enhver LambdaCDM- eller mørkt-stof-halomodel.
Derfor omdannes DM-siden i appendiks B (P1A) til et sæt »standardiserede stresstests«. Uden at ændre den fælles mapping eller lukningsprotokollen tilføjer P1A gradvist lavdimensionelle forbedringsgrene såsom SCAT, AC, FB, HIER_CMSCAT, CORE1P, lensing m og den kombinerede baseline DM_STD, mens EFT_BIN bevares som sammenligning. Kort sagt er P1A ikke en sammenligning mod kun én minimal DM-baseline; den måler et sæt almindelige, auditérbare DM-mekanismer med den samme »lukningslineal«.
Den præcise konklusionsramme brugt her |
Hovedtekst: EFT-familien klarer sig væsentligt bedre end den minimale DM_RAZOR i hovedsammenligningen. |
Appendiks B / P1A: Under flere lavdimensionelle, auditérbare DM-forbedringsgrene og DM_STD-stresstesten forbedres nogle DM-joint fits, men lukningsstyrken eliminerer ikke EFT_BIN’s fordel. |
Den sikreste formulering er derfor: Inden for P1/P1A’s data, mapping, parameterregnskab og lukningsprotokol viser EFT’s gennemsnitlige gravitationsrespons stærkere konsistens på tværs af data; det er ikke det samme som at udelukke alle modeller for mørkt stof. |
5.3 Lukningstest: P1’s vigtigste eksperimentelle syntaks
1. Fit kun med RC for at opnå et sæt RC-only posteriorprøver.
2. Retun ikke med GGL; brug RC-posterioren direkte til at forudsige GGL.
3. Brug den fulde kovarians til at beregne GGL-forudsigelsens score under den korrekte mapping, logL_true.
4. Permutér RC-bin→GGL-bin-korrespondancen tilfældigt for at beregne den negative kontrolscore, logL_perm.
5. Træk de to fra hinanden for at opnå lukningsstyrke: ΔlogL_closure = <logL_true> − <logL_perm>.
Analogien i almindeligt sprog |
En lukningstest er som en reeksamen på tværs af eksamenslokaler. Modellen lærer først mønstre i RC-lokalet og svarer derefter i GGL-lokalet. Hvis den har lært en fælles regel i stedet for et lokalt trick, bør den stadig svare godt efter at have skiftet lokale; hvis korrespondancen mellem eksamenslokalerne bevidst shuffles, bør fordelen forsvinde. |
5.4 Før læsning af de tekniske tabeller: Fire indgange
Tabel 5.4 | Læsevej til det næste sæt tekniske landskabstabeller
Indgang | Hvad skal man se på | Hvorfor det betyder noget |
Tabel S1a | RC+GGL joint-fit totalscore | Svar på: »Når de to datasæt ses samlet, hvis samlede forklaring er stærkere?« |
Tabel S1b | Lukningsstyrke, shuffle og robusthedsscanninger | Svar på: »Kan det, der blev lært fra RC, overføres til GGL?« |
Tabel B0 | Definitioner af flere DM-forbedringsgrene i P1A | Forhindrer P1 i at blive reduceret til »kun en sammenligning med minimal DM_RAZOR«. |
Tabel B1 | P1A-luknings- og joint-fit-scoreboard | Kontrollerer, om lukningsfordelen forsvinder, efter at DM styrkes. |
Layoutbemærkning |
Liggende sider begynder på næste side, så de brede tabeller fra den oprindelige rapport kan bevares intakte uden at slette kolonner eller komprimere dem, så de bliver ulæselige. Brødteksten har allerede givet en læsning i almindeligt sprog; de liggende tekniske tabeller er for læsere, der skal kontrollere værdier og modelgrene. |
Figur 0.1 | P1’s lukningstest-workflow i ét diagram
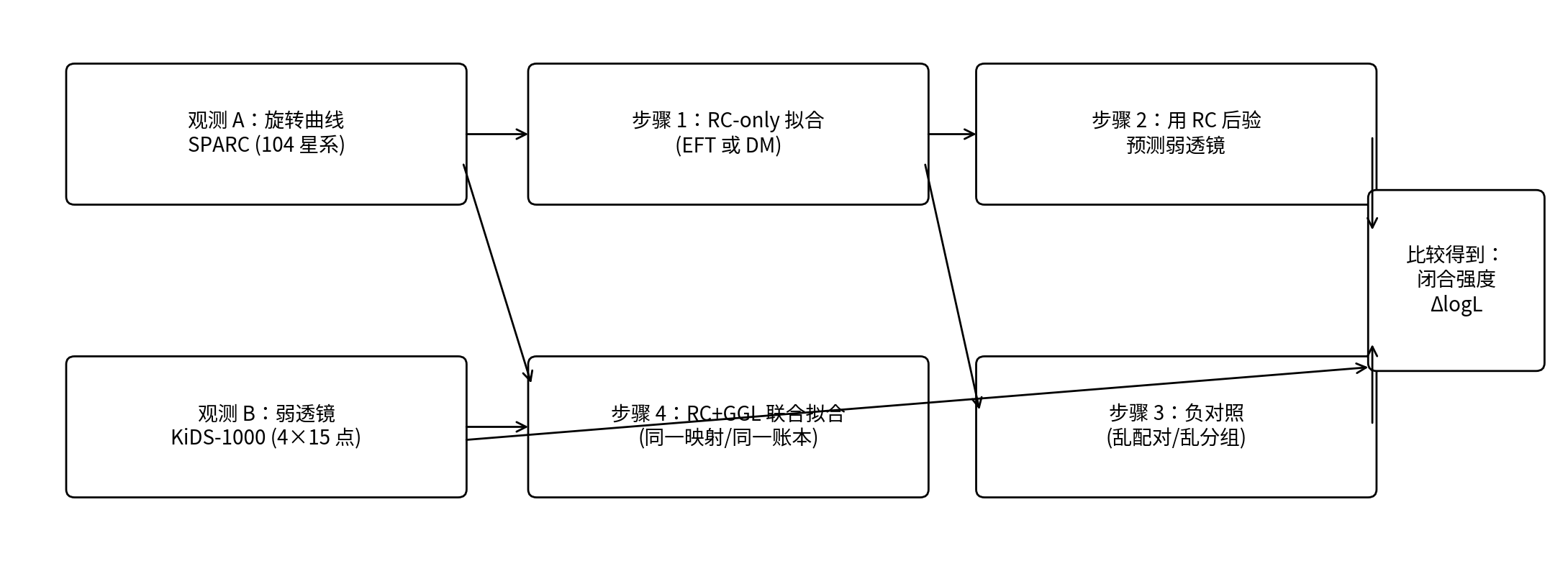
Bemærk: Den øverste kæde er »lukningstesten« (fit kun RC → brug RC-posterioren til at forudsige GGL); den nederste kæde er »joint fit« (score RC+GGL samlet). Til højre sammenlignes den sande mapping med den shufflede mapping for at opnå lukningsstyrke ΔlogL.
6 | Centrale tekniske tabeller: Hovedtabeller fra den oprindelige rapport og P1A-tabeller
Tabel S1a | Hovedmål for joint-fit-sammenligning (RC+GGL, streng; bevaret fra den oprindelige rapport)
Model (workspace) | W-kerne | k | Joint logL_total (bedste) | ΔlogL_total vs DM | AICc | BIC |
DM_RAZOR | ingen | 20 | -16927.763 | 0.0 | 33895.885 | 34010.811 |
EFT_BIN | ingen | 21 | -15590.552 | 1337.21 | 31223.501 | 31344.155 |
EFT_WEXP | eksponentiel | 21 | -15668.83 | 1258.932 | 31380.057 | 31500.711 |
EFT_WYUK | yukawa | 21 | -15772.936 | 1154.827 | 31588.268 | 31708.922 |
EFT_WPOW | powerlaw_tail | 21 | -15633.321 | 1294.442 | 31309.038 | 31429.692 |
Tabel S1b | Luknings- og robusthedsmål (streng; bevaret fra den oprindelige rapport)
Model (workspace) | Lukning ΔlogL (true-perm) | ΔlogL efter negativ-kontrol-shuffle | σ_int-scan ΔlogL-interval | R_min-scan ΔlogL-interval | cov-shrink-scan ΔlogL-interval |
DM_RAZOR | 126.678 | 22.725 | — | — | — |
EFT_BIN | 231.611 | 14.984 | 459–1548 | 1243–1289 | 1337–1351 |
EFT_WEXP | 171.977 | 6.04 | 408–1471 | 1169–1207 | 1259–1277 |
EFT_WYUK | 179.808 | 14.688 | 380–1341 | 1065–1099 | 1155–1166 |
EFT_WPOW | 280.513 | 6.672 | 457–1500 | 1203–1247 | 1294–1308 |
Tabel B0 | Definitioner af DM-forbedringsgrene i P1A (bevaret fra appendiks B i den oprindelige rapport)
Workspace | dm_model | Ny parameter (≤1) | Fysisk motivation (kerne) | Implementeringsprincip (auditvenlig) |
|---|---|---|---|---|
DM_RAZOR | NFW (fast c–M, ingen spredning) | — | Minimal, auditérbar LambdaCDM-halo-baseline; brugt som streng sammenligning med EFT | Fast fælles mapping; strengt parameterregnskab; bruges kun som baseline for relativ sammenligning |
DM_RAZOR_SCAT | NFW + c–M-spredning(legacy) | σ_logc | c–M-relationen har spredning; approksimeret med én-parameter lognormal spredning | ≤1 ny parameter; bruger stadig den fælles mapping; lukningsgevinst er acceptkriteriet |
DM_RAZOR_AC | NFW + adiabatisk kontraktion(legacy) | α_AC | Baryonisk indfald kan forårsage adiabatisk kontraktion af haloen; approksimeret med en én-parameter styrke | ≤1 ny parameter; mapping uændret; rapporterer AICc/BIC-ændringer og lukningsgevinst |
DM_RAZOR_FB | NFW + feedback-kerne(legacy) | log r_core | Feedback kan skabe en indre kerne; approksimeret med en én-parameter kerneskala | ≤1 ny parameter; samme luknings-/negativ-kontrol-ramme; RC-only-forbedring er ikke det eneste mål |
DM_HIER_CMSCAT | Hierarkisk c–M-spredning + prior | σ_logc(hier) | En mere standard hierarkisk c_i∼logN(c(M_i),σ_logc); påvirker den fælles RC- og GGL-posterior | Eksplicit prior; latent c_i marginaliseret; forbliver lavdimensionel og auditérbar |
DM_CORE1P | 1-parameter core-proxy (inspireret af coreNFW/DC14) | log r_core | Bruger en én-parameter core-proxy for hovedvirkningen af baryonisk feedback og undgår højdimensionelle detaljer om stjernedannelse | Citerer standardlitteratur; ≤1 ny parameter; bundet til lukningstesten |
DM_RAZOR_M | NFW + lensing shear-kalibrerings-nuisance | m_shear(GGL) | Absorberer en central systematik på svag-linse-siden med en effektiv parameter og reducerer risikoen for at behandle systematik som fysik | Nuisance registreres eksplicit; må ikke tilbagevirke på RC; resultater vurderes primært efter lukningsrobusthed |
DM_STD | Standardiseret DM-baseline (HIER_CMSCAT + CORE1P + m) | σ_logc + log r_core (+ m_shear) | Samler de tre mest almindelige indvendinger i én stadig lavdimensionel standardiseret baseline | Rapporterer parameterregnskab og informationskriterier samlet; lukning er hovedmålet; bruges som den stærkeste DM-forsvarssammenligning |
Tabel B1 | P1A-scoreboard (større er bedre; bevaret fra appendiks B i den oprindelige rapport)
Modelgren (workspace) | Δk | RC-only bedste logL_RC (Δ) | Lukningsstyrke ΔlogL_closure (Δ) | Joint bedste logL_total (Δ) |
DM_RAZOR | 0 | -15702.654 (+0.000) | 122.205 (+0.000) | -27347.068 (+0.000) |
DM_RAZOR_SCAT | 1 | -15702.294 (+0.361) | 121.236 (-0.969) | -23153.311 (+4193.758) |
DM_RAZOR_AC | 1 | -15703.689 (-1.035) | 121.531 (-0.674) | -23982.557 (+3364.511) |
DM_RAZOR_FB | 1 | -15496.046 (+206.609) | 129.454 (+7.249) | -27478.531 (-131.463) |
DM_HIER_CMSCAT | 1 | -15702.644 (+0.010) | 121.978 (-0.227) | -23153.160 (+4193.908) |
DM_CORE1P | 1 | -15723.158 (-20.504) | 122.056 (-0.149) | -27336.258 (+10.810) |
DM_RAZOR_M | 0 (+m) | -15702.654 (+0.000) | 122.205 (+0.000) | -27340.451 (+6.617) |
DM_STD | 2 (+m) | -15832.203 (-129.549) | 105.690 (-16.515) | -22984.445 (+4362.623) |
EFT_BIN | 1 | -14631.537 (+1071.117) | 204.620 (+82.415) | -19001.142 (+8345.926) |
Sådan læses tabel B1 (P1A-scoreboard) |
• Δk: nyligt tilføjede frihedsgrader (større betyder en mere kompleks model; mere kompleks betyder ikke automatisk bedre). • Fokuser på to kolonner: lukningsstyrke ΔlogL_closure(Δ) (større betyder mere selvkonsistens i overførsel) og Joint best logL_total(Δ) (joint-fit totalscoren). • Værdien i parentes, (Δ), er forskellen relativt til DM_RAZOR og gør direkte sammenligning lettere. |
• Hovedspørgsmålet i denne tabel er, om lukningsfordelen forsvinder, efter at DM-baselinen er »rimeligt styrket«. • Læsetip: DM_STD forbedrer joint-scoren markant, men dens lukningsstyrke falder; EFT_BIN forbliver stadig højere i lukningsstyrke. |
I én sætning: Inden for dette lavdimensionelle, auditérbare sæt af DM-forbedringer giver forbedring af joint fit ikke automatisk stærkere lukning; lukning, dvs. overførbarhed, forbliver nøglekriteriet. |
7 | Hvordan bør hovedresultaterne læses?
7.1 Joint fit: Set på tværs af begge datasæt er EFT’s hovedsammenligningsscore højere
Tabel S1a og figur S4 viser, at EFT-familien, under samme data, samme fælles mapping og omtrent samme parameterskala, har en samlet ΔlogL_total på 1155–1337 relativt til DM_RAZOR. En almindelig læser kan forstå det sådan: Under den samme scoringsregel anvendt på RC og GGL samlet får EFT-modellerne i hovedsammenligningen en højere totalscore.
7.2 Lukningstest: Det P1 mest vil fremhæve er »overførbarhed«
Høj lukningsstyrke betyder, at parametre udledt alene fra RC kan forudsige GGL bedre uden at kigge på GGL igen. I P1-rapporten er EFT’s ΔlogL_closure 172–281, mens DM_RAZOR er 127. Dette resultat betyder mere end at sige, at »hver model passer sine egne data godt«, fordi det begrænser modellens frihed på det andet datasæt.
7.3 Negativ kontrol: Hvorfor er »signalkollaps« en god ting?
Efter at P1 tilfældigt shuffler korrespondancen mellem RC-bin→GGL-bin-grupperne, falder EFT’s lukningssignal til intervallet 6–23. For en almindelig læser er dette trin som en anti-snyd-kontrol: Hvis lukningsfordelen blot var skabt af kode, enheder, kovarianshåndtering eller fitting-tilfældighed, kunne fordelen bestå selv under en shuffled korrespondance. I stedet kollapser den faktiske fordel, hvilket viser, at den afhænger af den korrekte mapping.
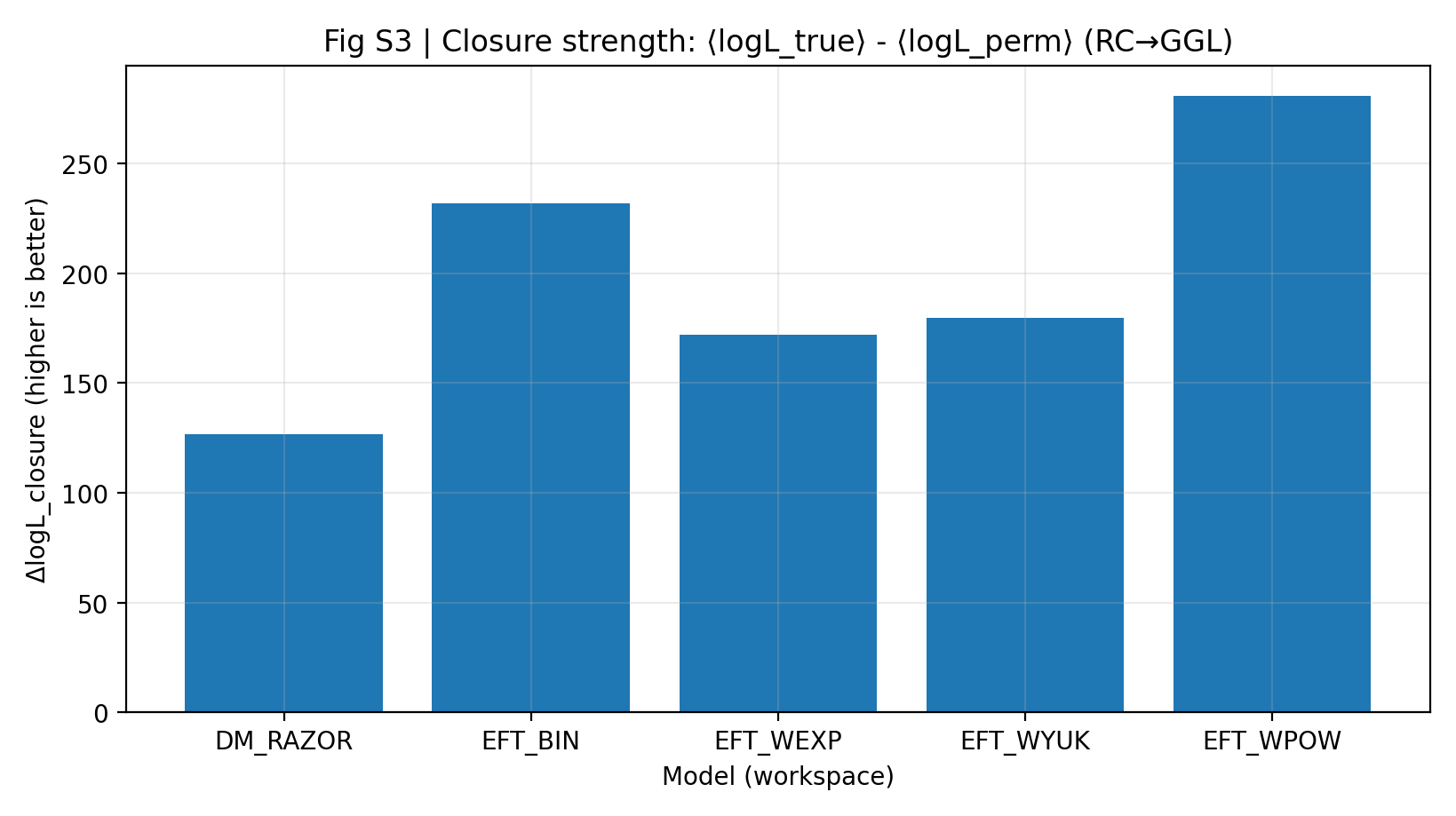
Figur S3 | Lukningsstyrke (større er bedre): Gennemsnitlig log-likelihood-fordel for RC-only → GGL-forudsigelse.
Sådan læses denne figur |
Denne figur er kernen i P1. Jo højere søjlen er, desto bedre overføres den information, der er lært fra RC, til GGL. |
EFT-familien ligger samlet højere end DM_RAZOR, hvilket indikerer stærkere EFT-lukning på tværs af sonder i eksperimentet »lær RC først, forudsig derefter GGL«. |
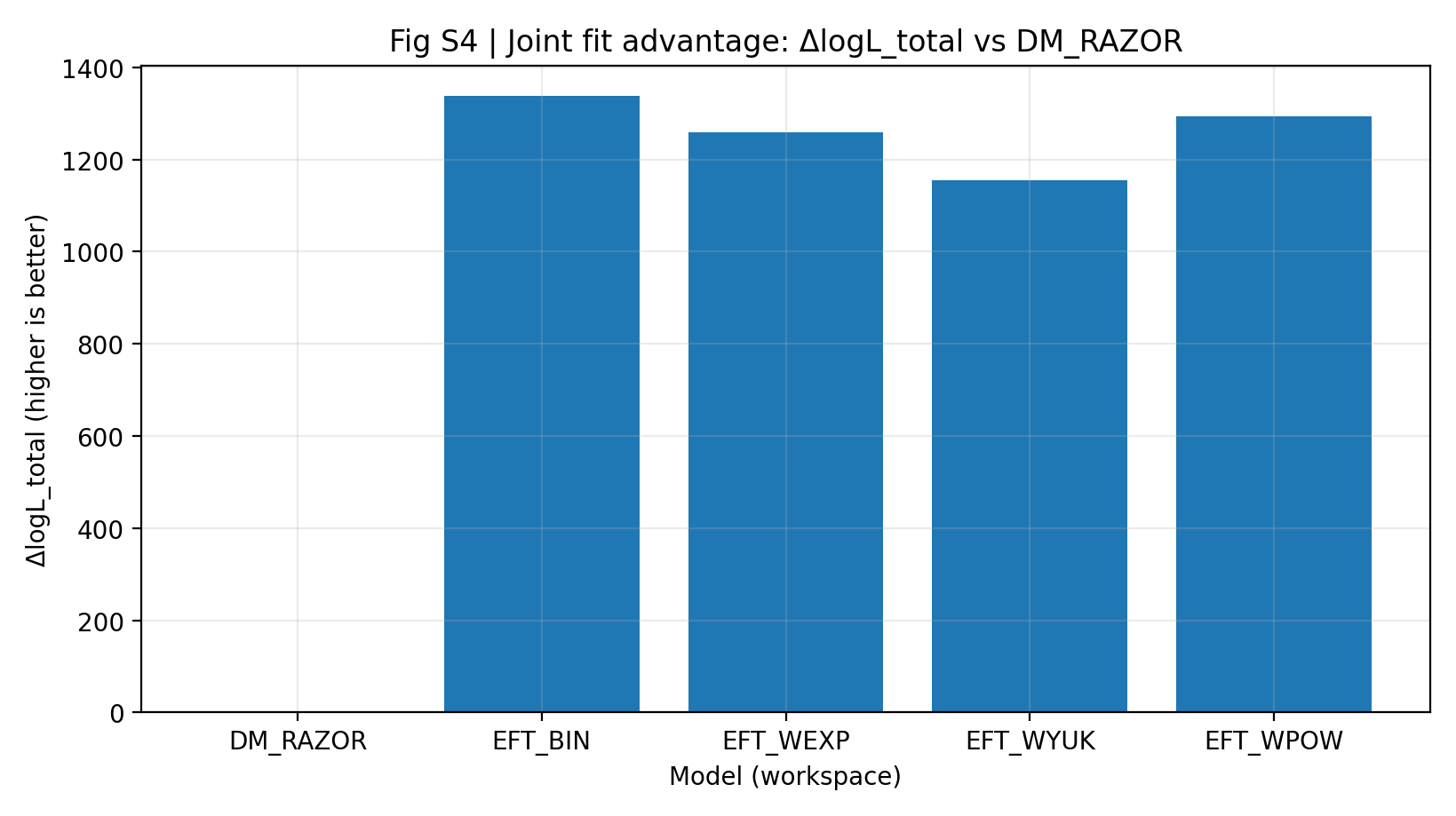
Figur S4 | Joint-fit-fordel (større er bedre): RC+GGL bedste logL_total relativt til DM_RAZOR.
Sådan læses denne figur |
Denne figur viser totalscoren, efter at RC og GGL er kombineret. |
Alle EFT-modeller ligger klart over 0, hvilket indikerer, at EFT-fordelen i hovedsammenligningen ikke er et lokalt enkeltpunktseffekt, men et samlet mønster i den fælles analyse. |
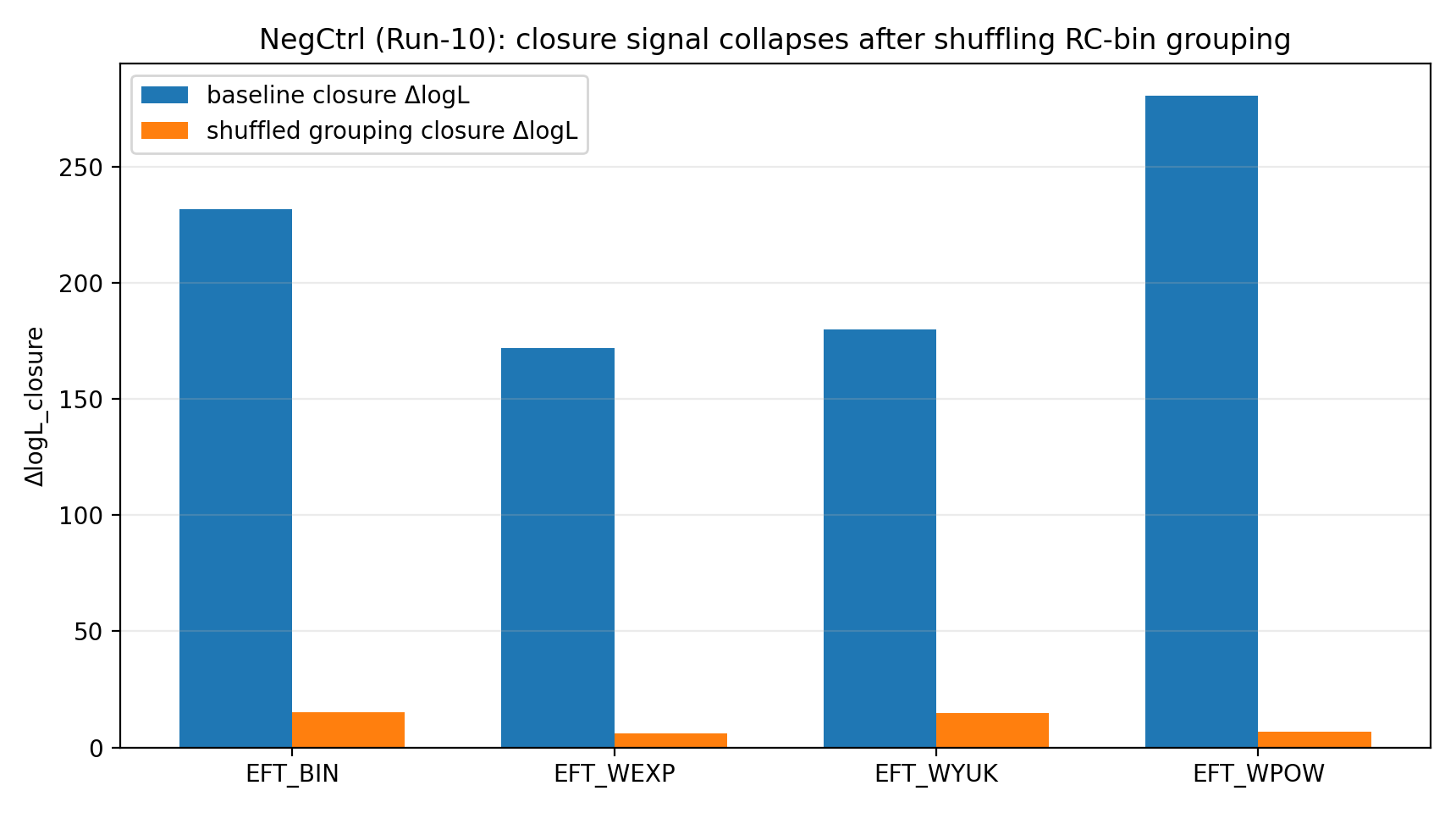
Figur R1 | Negativ kontrol: Lukningssignalet falder kraftigt efter shuffling af grupperingen.
Sådan læses denne figur |
Denne figur viser, at når den korrekte RC↔GGL-bin-relation brydes, falder lukningssignalet kraftigt. |
Det får P1-resultatet til at ligne ægte konsistens i mapping på tværs af data snarere end et numerisk sammentræf, der kan opnås under vilkårlige mappings. |
8 | Robusthed og kontroller: Hvordan undgår P1 at være »bare et flot fit«?
Den letteste indvending mod en teknisk rapport er, om fordelen kommer fra én støjindstilling, ét datasnit i centralområdet, én kovariansbehandling eller overfitting. P1 håndterer dette med flere stresstests.
Tabel 2 | Sådan læses P1’s robusthedstests og negative kontroller
Test | Tvivl den forsøger at udelukke | Sådan læses den |
σ_int scan | Hvis RC indeholder ekstra ukendt spredning, forbliver konklusionen så stabil? | Efter at RC-fejlene lempes, forbliver EFT-rangeringen og fordelens størrelsesorden stabil. |
R_min scan | Hvis man ikke fuldt ud stoler på galaksernes centrale regioner, forbliver konklusionen så stabil? | Efter trimning af de centrale regioner bevarer EFT stadig en positiv fordel. |
cov-shrink scan | Hvis GGL-kovariansestimatet er usikkert, forbliver konklusionen så stabil? | Efter shrinkage af kovariansen mod diagonalen er fordelen ikke følsom. |
Ablationstrappe | Afhænger EFT af unødvendig kompleksitet for at tvinge et fit? | Den fulde EFT_BIN understøttes af informationskriterierne. |
LOO-udeladt forudsigelse | Forklarer modellen kun data, den allerede har set? | Efter udeladelse af en GGL-bin viser modellen stadig stærk generaliseringsevne. |
RC-bin shuffle | Kommer lukning fra den sande mapping? | Lukning falder efter shuffling af grupperingen, hvilket understøtter mapping-afhængighed. |
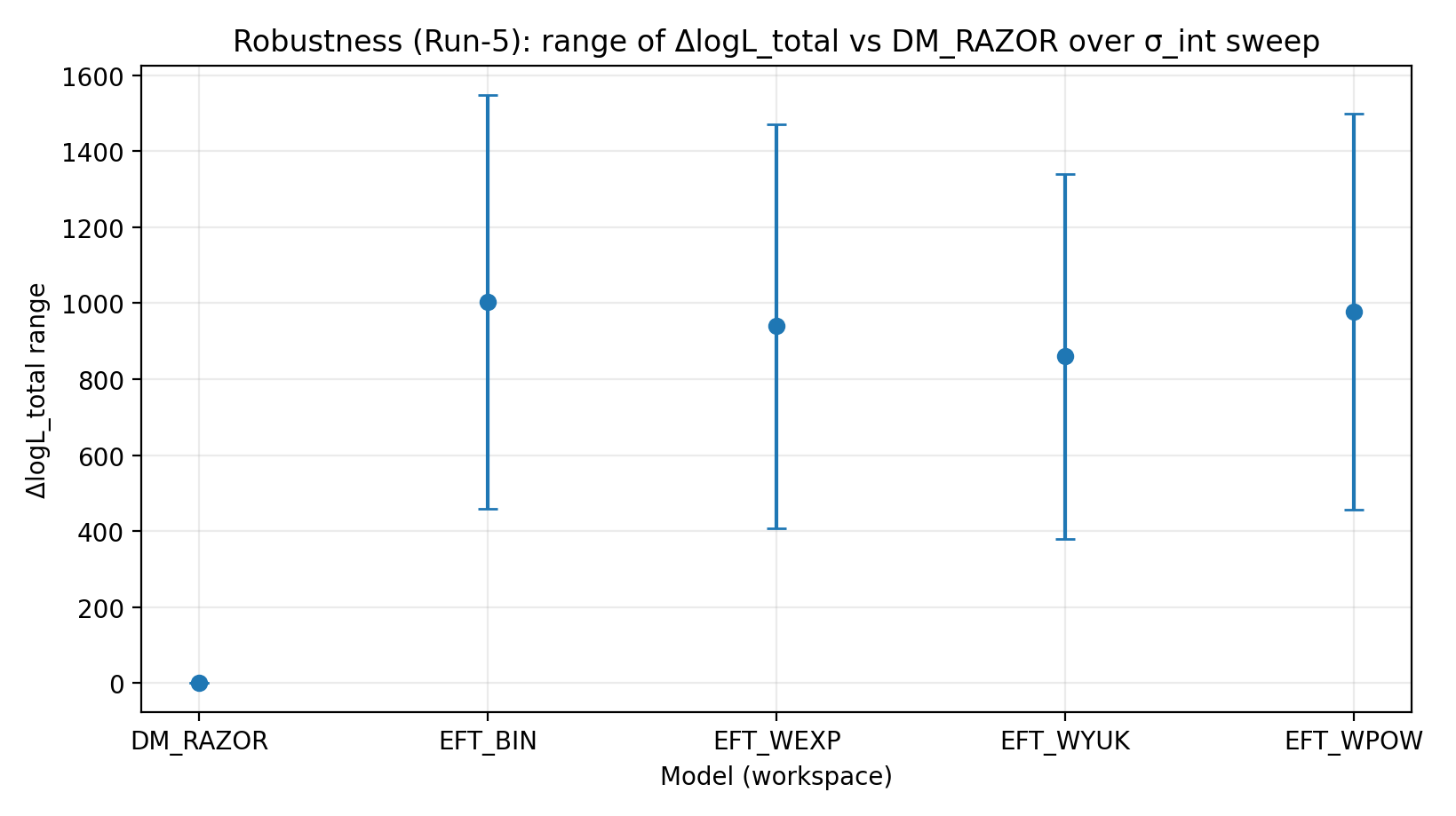
Figur R2 | Interval for ΔlogL_total under σ_int-scanningen (større er bedre).
Sådan læses denne figur |
Tester, om EFT’s føring består efter ændringer i den antagne intrinsiske RC-spredning. |
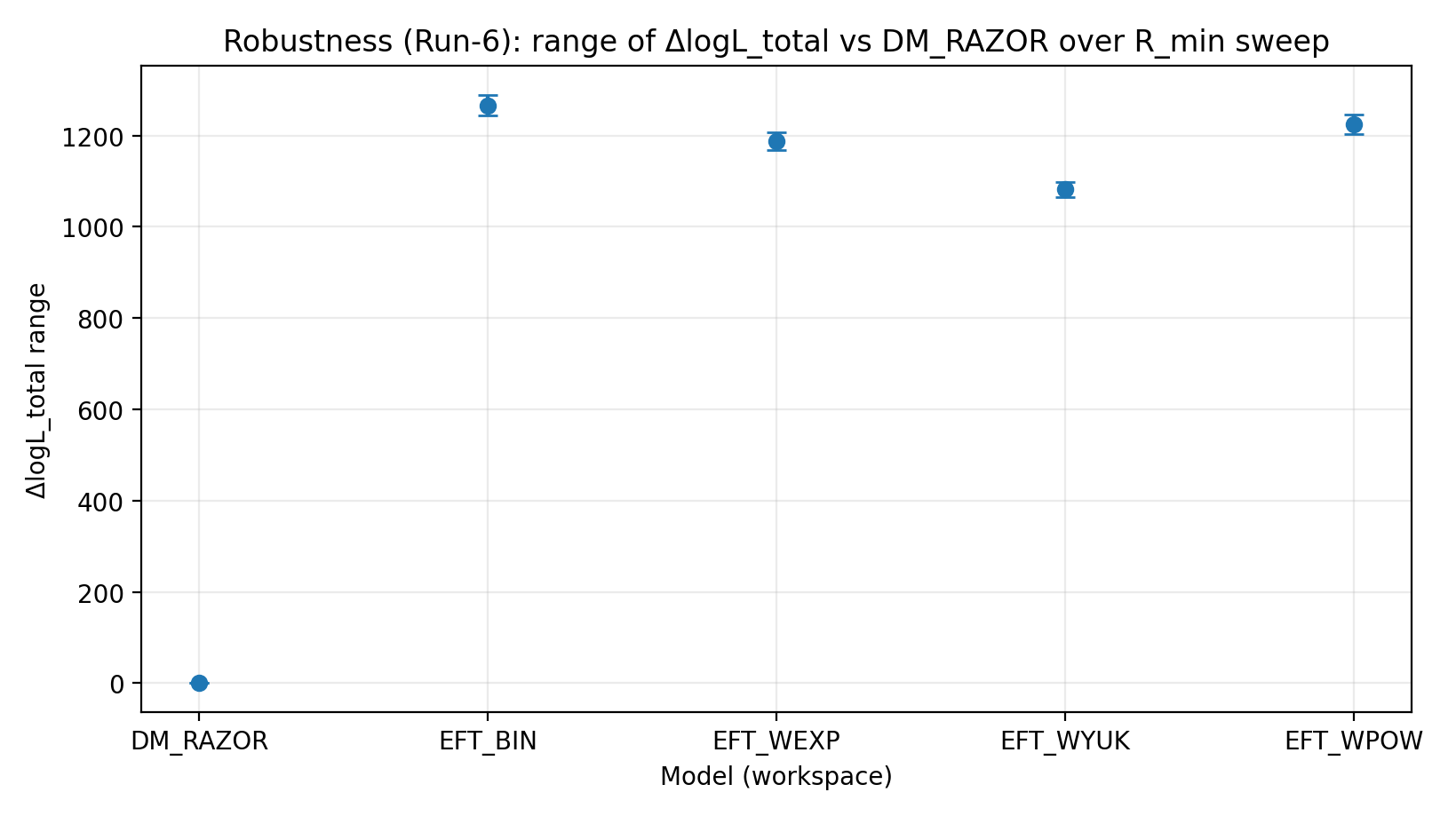
Figur R3 | Interval for ΔlogL_total under R_min-scanningen (større er bedre).
Sådan læses denne figur |
Tester, om EFT’s fordel forbliver stabil efter trimning af komplekse centrale regioner. |
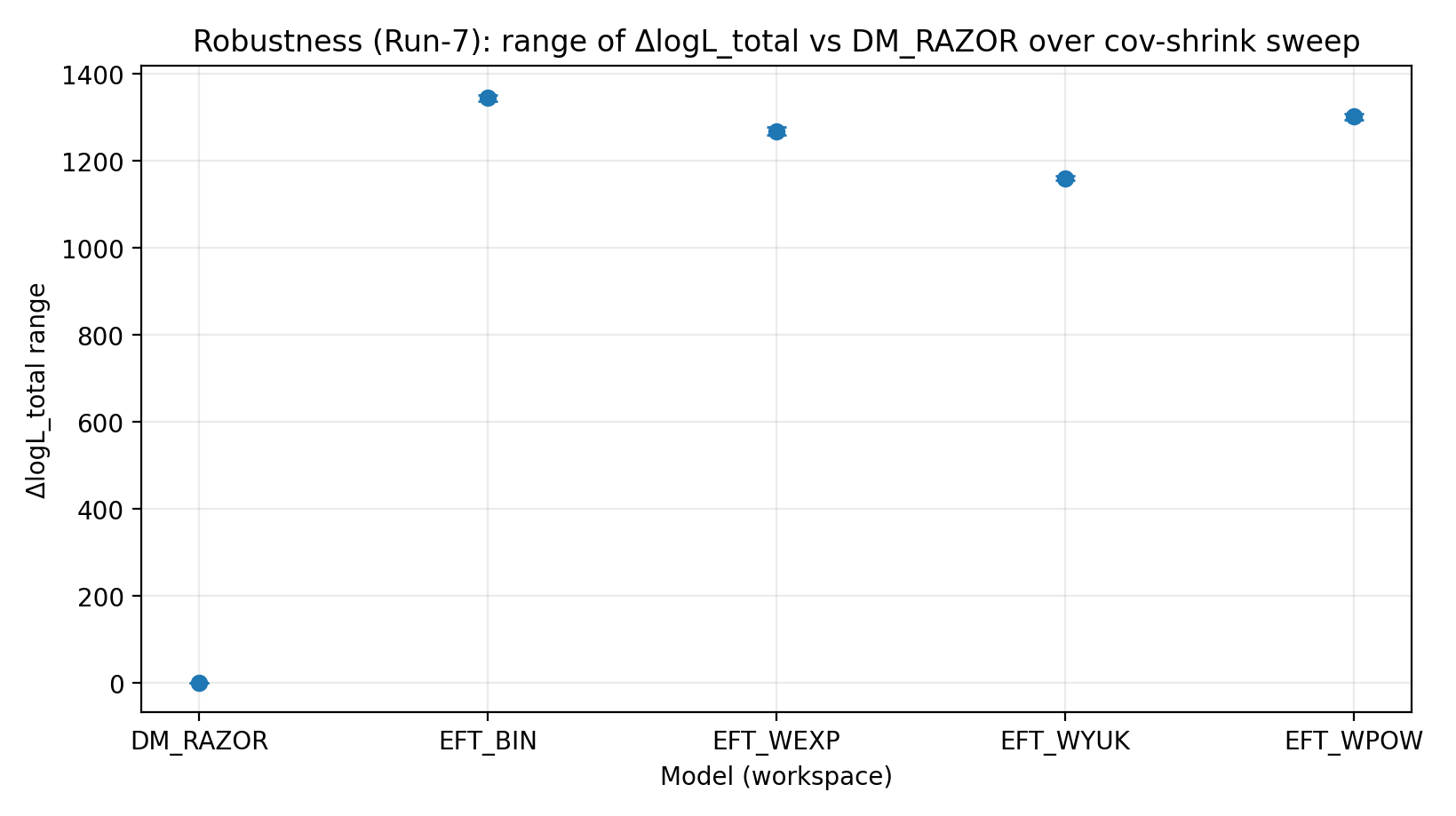
Figur R4 | Interval for ΔlogL_total under cov-shrink-scanningen (større er bedre).
Sådan læses denne figur |
Tester, om rangeringen er følsom over for ændringer i behandlingen af svag-linse-kovarians. |
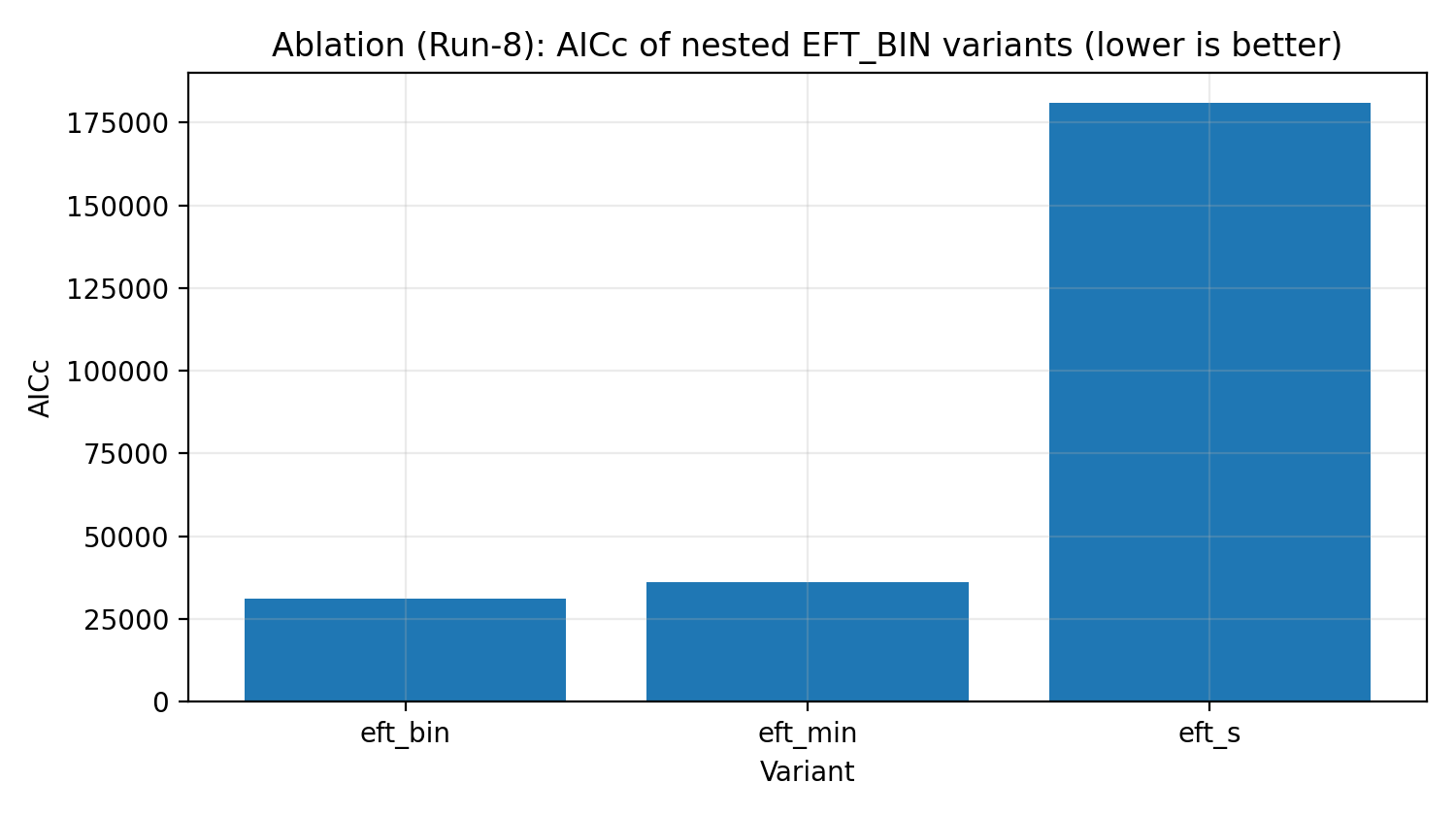
Figur R5 | EFT_BIN-ablationstrappen (AICc, mindre er bedre).
Sådan læses denne figur |
Tester, om den fulde EFT_BIN er nødvendig for at forklare dataene, snarere end blot at tilføje unødvendige parametre. |
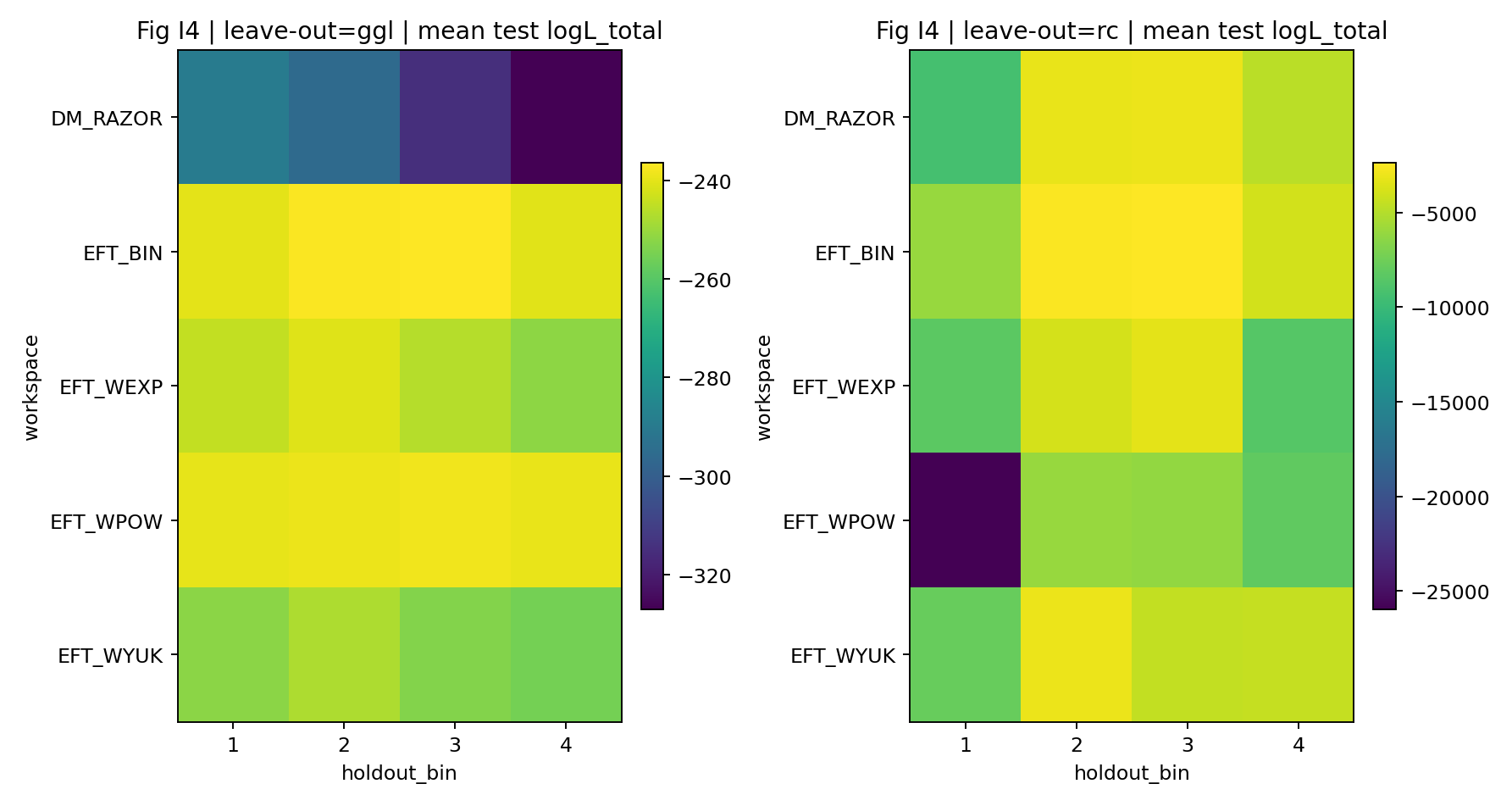
Figur R6 | LOO: Log-likelihood-fordeling for udeladte bins.
Sådan læses denne figur |
Tester, om modellen stadig har forudsigelsesevne på usete GGL-bins. |
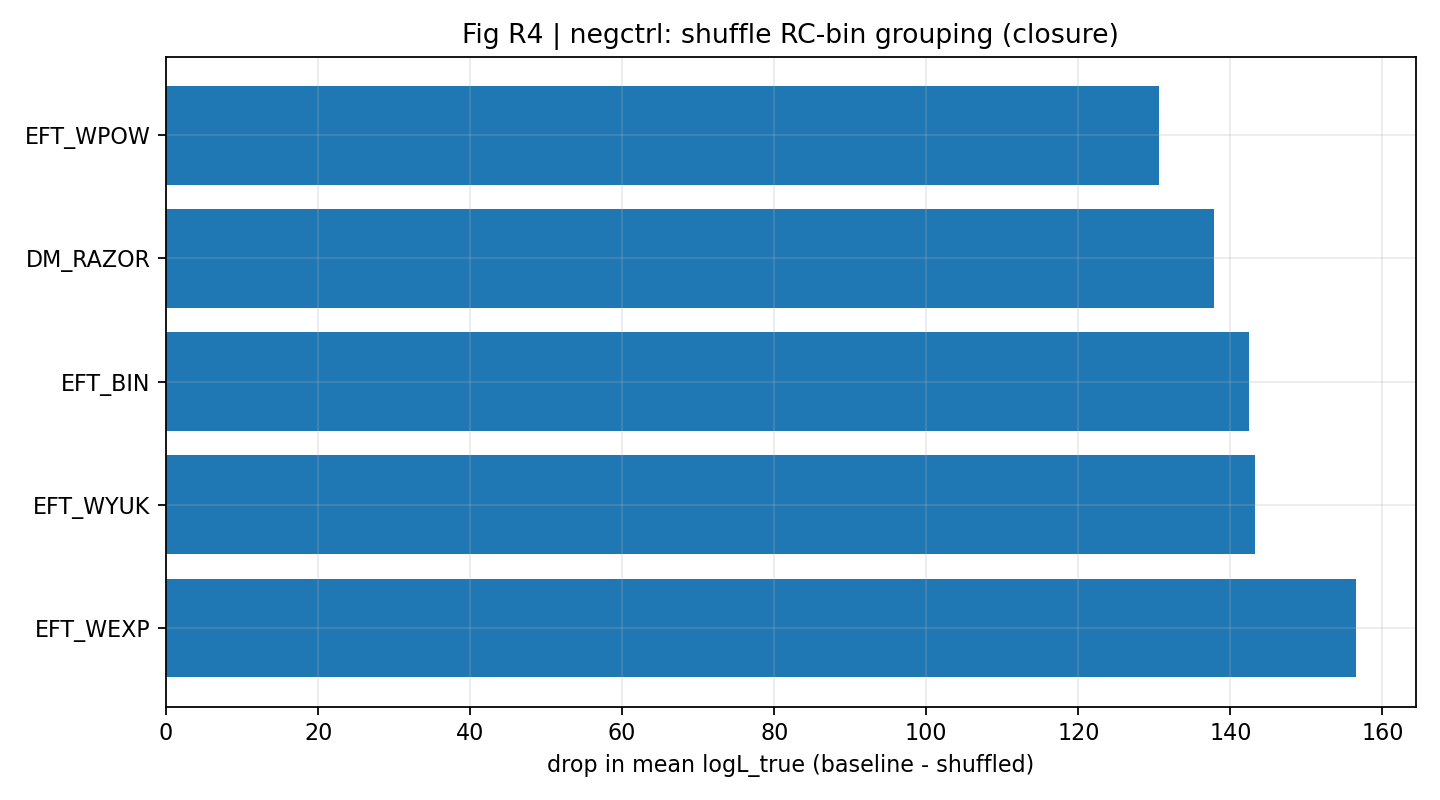
Figur R7 | Negativ kontrol: Shuffled mapping giver et tydeligt fald i lukningens mean logL_true.
Sådan læses denne figur |
Viser yderligere, set fra mean logL_true, at lukning afhænger af den korrekte mapping på tværs af data. |
9 | P1A: Hvorfor »flere DM-modeller i appendikset« er en vigtig korrektion
Dette afsnit spørger ikke: »Slog EFT kun én minimal DM_RAZOR-baseline?« Det spørger, om konklusionerne fra lukningstesten og joint fit ændrer sig, når DM-baselinen styrkes inden for et lavdimensionelt, reproducerbart og klart registreret parameterregnskab (P1A). Med andre ord forsøger P1A at mindske indvendingen om, at »I valgte blot en alt for svag DM-baseline«, og flytter diskussionen hen imod, om lukningsadfærden stadig adskiller sig under et sæt auditérbare DM-forbedringer.
P1A er ikke designet til at udtømme al mulig LambdaCDM-halomodellering, og den gør heller ikke DM-siden til en højdimensionel, ikke-auditérbar fitter. Den vælger lavdimensionelle, reproducerbare forbedringer med et klart parameterregnskab: koncentrationsspredning, adiabatisk kontraktion, feedback-kerne, hierarkisk c–M-spredningsprior, én-parameter core-proxy, nuisance for shear-kalibrering i svag linsevirkning og den kombinerede DM_STD-baseline.
Hovedlæsning af P1A |
Blandt de tre legacy-grene giver kun feedback/core en lille nettoforøgelse af lukningsstyrken; SCAT og AC giver ikke netto-lukningsgevinster. |
DM_HIER_CMSCAT, DM_RAZOR_M og DM_CORE1P har meget lille effekt på lukningsstyrken eller viser ikke nogen signifikant nettoforbedring. |
DM_STD kan forbedre joint logL betydeligt, men dens lukningsstyrke falder, hvilket tyder på, at den primært forbedrer fleksibiliteten i joint fit snarere end RC→GGL-overførselsforudsigelseskraften. |
EFT_BIN bevarer stadig højere lukningsstyrke og en joint-fit-fordel i P1A tabel B1; derfor bør P1’s kernepåstand ikke reduceres til »den slog kun minimal DM_RAZOR«. |
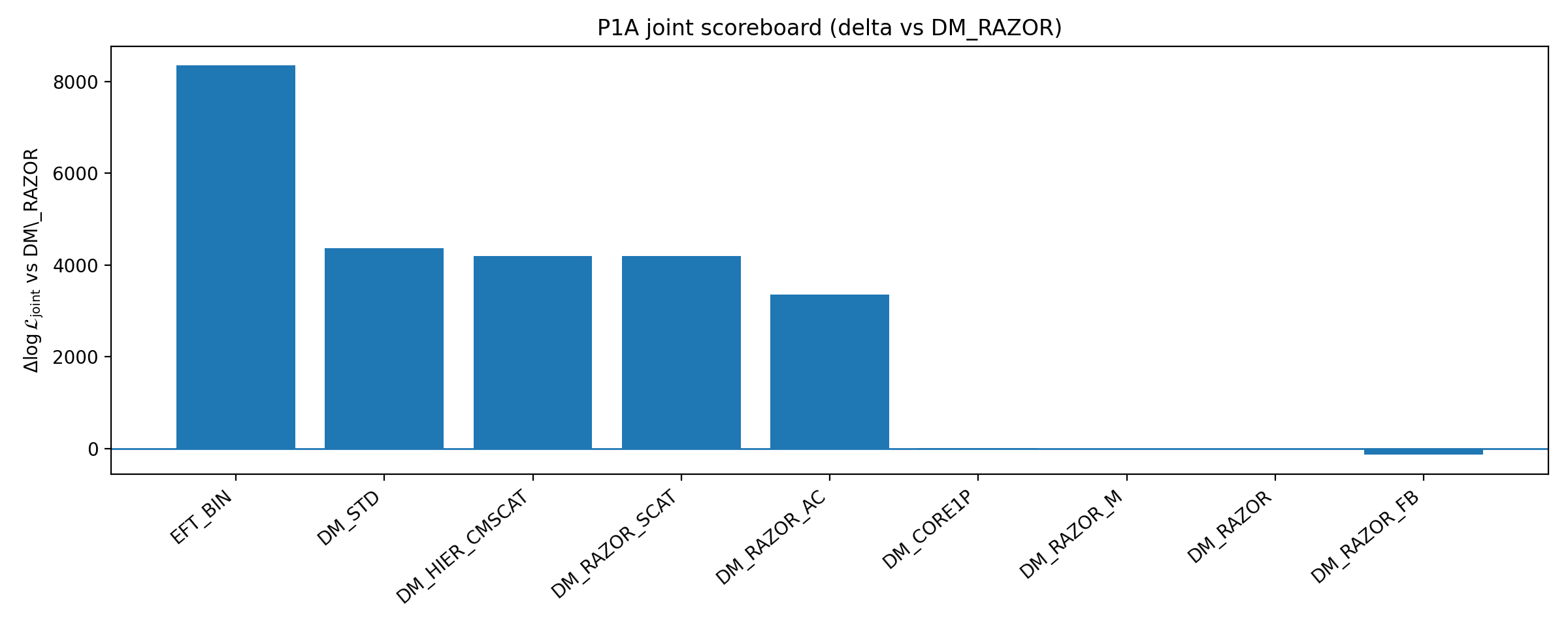
Figur B1 | P1A-scoreboard: Lukning og joint ΔlogL relativt til baseline (større er bedre).
Sådan læses denne figur |
Denne figur viser præstationen for flere DM-forbedringsgrene relativt til baselinen. |
Dens betydning er ikke »al DM er udelukket«, men snarere dette: Inden for de lavdimensionelle, auditérbare DM-forbedringer valgt af P1A fjerner styrkelse af DM ikke EFT_BIN’s lukningsfordel. |
10 | Hvorfor P1-eksperimentet betyder noget
10.1 Metodologisk betydning: At sætte »lukning på tværs af sonder« over »fitting af én sonde«
Teori på galakseskala kan let sidde fast i, om en model kan tilpasse et bestemt sæt rotationskurver. P1 løfter spørgsmålet ét niveau: Kan parametre lært fra RC forudsige svag linsevirkning uden retuning til GGL? Det gør P1 fra en »fitting-konkurrence« til en »overførsels-forudsigelsestest«.
10.2 Transparensbetydning: At behandle reproducerbarhedskæden som en del af resultatet
Et vigtigt bidrag fra P1 er, at den frigiver data, tabeller og figurer, run-labels, negative kontroller, reproduktionspakke og auditkæde samlet. Det betyder noget for både tilhængere og kritikere: Diskussionen kan vende tilbage til de samme offentlige data, den samme mapping, de samme scripts og de samme mål i stedet for at sammenligne slogans.
10.3 Fysisk betydning: En stærk stresstest for retninger med »gravitation uden mørkt stof«
I gravitationsretninger uden mørkt stof kan mange modeller forklare en del af rotationskurverne eller RAR. Den sværere opgave er også at bestå svag-linse-aflæsninger og vise under negative kontroller, at signalet afhænger af den korrekte mapping. P1 er vigtig, fordi den placerer EFT’s gennemsnitlige gravitationsrespons i en protokol som en ekstern eksamen: RC er træningsbanen, GGL er overførselsfeltet, og shuffle er anti-snyd-feltet.
10.4 Er dette et vigtigt eksperiment for feltet »gravitation uden mørkt stof«?
Forsigtigt formuleret: Hvis P1’s databehandling, reproduktionspakke og lukningsprotokol holder under ekstern gennemgang, kan den betragtes som et RC+GGL-lukningseksperiment, der er værd at tage alvorligt i retninger med gravitation uden mørkt stof / modificeret gravitation. Dets betydning ligger ikke i sloganet »mørkt stof er væltet«, men i at levere et kriterium på tværs af sonder, som kan reproduceres, udfordres og udvides.
Findes der allerede RC+GGL-forudsigelses-lukningsrammer på samme niveau? |
Der findes relevante rammer og observationstraditioner: MOND/RAR organiserer mange rotationskurvefænomener godt; KiDS-1000-arbejdet om svag-linse-RAR sammenlignede også MOND, Verlindes emergente gravitation og LambdaCDM-modeller; LambdaCDM kan også forklare nogle svag-linse-/dynamiske fænomener gennem galakse–halo-forbindelser, gashaloer og feedbackmodellering. |
Men P1’s præcise påstand er ikke, at »ingen anden ramme i verden kan forklare RC+GGL«. Den er snarere, at EFT under P1’s egen offentlige protokol — fast mapping, RC-only→GGL-lukning, shuffle-negative kontroller, parameterregnskab og P1A-stresstests med flere DM-varianter — rapporterer stærkere lukningspræstation. |
Med andre ord er den del af P1, der er mest værd at teste eksternt, dens konkrete, reproducerbare sammenligningsprotokol. Et meget værdifuldt næste skridt er at se, om MOND/RAR, LambdaCDM/HOD, hydrodynamiske simuleringer eller andre modificeret-gravitation-rammer kan nå samme eller højere lukningsscores under den samme protokol. |
11 | Hvad kan P1 konkludere, og hvad kan den ikke konkludere?
Tabel 3 | Grænserne for P1’s konklusioner
Kan konkluderes | Under P1’s RC+GGL-data, faste mapping og hovedsammenligningsprotokol har EFT-familien højere joint-fit-scores og lukningsstyrke end den minimale DM_RAZOR. |
Kan konkluderes | Inden for P1A’s lavdimensionelle, auditérbare DM-forbedringsområde eliminerer flere DM-forbedringer ikke EFT_BIN’s lukningsfordel. |
Kan konkluderes | Den shuffle-negative kontrol viser, at lukningssignalet afhænger af den korrekte mapping på tværs af data og ikke kan opnås under vilkårlige mappings. |
Kan ikke konkluderes | Man kan ikke sige, at P1 har væltet alle modeller for mørkt stof. P1A udtømmer stadig ikke ikke-sfæricitet, miljøafhængighed, komplekse galakse–halo-forbindelser, højdimensionel feedback eller fulde kosmologiske simuleringer. |
Kan ikke konkluderes | Man kan ikke sige, at den komplette EFT-ramme er bevist fra første principper. P1 tester kun det fænomenologiske lag af gennemsnitlig gravitationsrespons. |
Kan ikke konkluderes | Man kan ikke sige, at alle systematikker er udelukket. P1 giver kun robusthedsevidens inden for de anførte stresstests og auditomfang. |
12 | Ofte stillede spørgsmål fra almindelige læsere
Q1: Siger dette, at »mørkt stof ikke findes«?
Nej. P1’s konklusioner skal begrænses til de data, den protokol og de sammenligningsmodeller, der bruges her. P1A går ud over den minimale DM_RAZOR, men den repræsenterer stadig ikke alle mulige modeller for mørkt stof.
Q2: Siger dette, at »EFT er bevist«?
Også nej. P1 tester EFT som en parameterisering af gennemsnitlig gravitationsrespons og viser stærkere præstation i RC→GGL-lukning; den mikroskopiske mekanisme og den komplette teori er ikke P1’s konklusion.
Q3: Hvorfor ikke rapportere en signifikansværdi direkte i σ?
P1 bruger ensartede likelihood-scores, informationskriterier og lukningsforskelle. ΔlogL er en relativ fordel under den samme scoringsregel; den svarer ikke til én enkelt σ-værdi.
Q4: Hvorfor shuffle RC-bin→GGL-bin?
Dette er en negativ kontrol. Et ægte signal på tværs af sonder bør afhænge af den korrekte mapping; hvis det forbliver lige så stærkt efter shuffling, ville det i stedet pege på mulig implementeringsbias eller et statistisk falsk signal.
Q5: Hvad bør P1 gøre næste gang?
Udvid den samme protokol til flere data, flere DM-sammenligninger, mere komplekse systematikker og flere modificeret-gravitation-rammer — især på måder, der lader eksterne teams genteste under det samme lukningsmål.
13 | Miniordliste
Tabel 4 | Miniordliste
Term | Forklaring i én sætning |
Rotationskurve (RC) | Relationen mellem radius og rotationshastighed i en galakseskive, brugt til at udlede effektiv gravitation i skiven. |
Svag linsevirkning (GGL) | Et mål for den gennemsnitlige gravitations-/massefordeling omkring forgrundsgalakser via den statistiske forvrængning af baggrundsgalaksers former. |
Lukningstest | Bruger RC-posterioren til at forudsige GGL og sammenligner derefter med den negative kontrol produceret af shuffled mapping. |
Negativ kontrol | Bryder bevidst en central struktur for at se, om signalet forsvinder; bruges til at udelukke falske signaler. |
NFW-halo | En tæthedsprofil for haloer af mørkt stof, som ofte bruges i modeller for koldt mørkt stof. |
c–M-relation | Relationen mellem koncentrationen c og massen M for en halo af mørkt stof; om spredning tillades, påvirker modellens fleksibilitet. |
DM_STD | Den standardiserede DM-stresstestgren i P1A, som kombinerer flere lavdimensionelle DM-forbedringer og et lensing-nuisance-led. |
ΔlogL | Log-likelihood-forskellen mellem to modeller under den samme scoringsregel; en positiv værdi betyder, at den førstnævnte er bedre. |
Kovarians | En matrixbeskrivelse af korrelationer mellem datapunkter; svag-linse-data kræver normalt den fulde kovarians. |
14 | Foreslået læsevej og citationsindgange
1. Læs først afsnit 0–2 i denne guide for at fastlægge P1’s spørgsmål og EFT’s bevidst tilbageholdne rolle i P1.
2. Læs derefter figur S3, figur S4 og tabel S1a/S1b for at forstå lukningsstyrke, joint fitting og negative kontroller.
3. Hvis du er bekymret for, at »DM-baselinen er for svag«, så gå direkte til afsnit 9 og tabel B1 / figur B1.
4. For teknisk verifikation, vend tilbage til den tekniske P1-rapport v1.1, Tables & Figures Supplement og full_fit_runpack.
Hovedindgange til arkiver |
P1 teknisk rapport (udgivelsesniveau, Concept DOI): 10.5281/zenodo.18526334 |
P1 fuld reproduktionspakke (Concept DOI): 10.5281/zenodo.18526286 |
EFT struktureret vidensbase (valgfri, Concept DOI): 10.5281/zenodo.18853200 |
Licensbemærkning: Den tekniske rapport bruger CC BY-NC-ND 4.0; den fulde reproduktionspakke bruger CC BY 4.0 (den tekniske rapport og Zenodo-arkiverne er autoritative). |
15 | Referencer og ekstern baggrund
McGaugh, S. S., Lelli, F., & Schombert, J. M. (2016). The Radial Acceleration Relation in Rotationally Supported Galaxies. Physical Review Letters, 117, 201101. DOI: 10.1103/PhysRevLett.117.201101.
Famaey, B., & McGaugh, S. S. (2012). Modified Newtonian Dynamics (MOND): Observational Phenomenology and Relativistic Extensions. Living Reviews in Relativity, 15, 10. DOI: 10.12942/lrr-2012-10.
Brouwer, M. M., Oman, K. A., Valentijn, E. A., et al. (2021). The weak lensing radial acceleration relation: Constraining modified gravity and cold dark matter theories with KiDS-1000. Astronomy & Astrophysics, 650, A113. DOI: 10.1051/0004-6361/202040108.
Mistele, T., McGaugh, S., Lelli, F., Schombert, J., & Li, P. (2024). Indefinitely Flat Circular Velocities and the Baryonic Tully-Fisher Relation from Weak Lensing. The Astrophysical Journal Letters, 969, L3 / arXiv:2406.09685.
Bullock, J. S., & Boylan-Kolchin, M. (2017). Small-Scale Challenges to the LambdaCDM Paradigm. Annual Review of Astronomy and Astrophysics, 55, 343–387. DOI: 10.1146/annurev-astro-091916-055313.
Lelli, F., McGaugh, S. S., & Schombert, J. M. (2016). SPARC: Mass Models for 175 Disk Galaxies with Spitzer Photometry and Accurate Rotation Curves. The Astronomical Journal, 152, 157. DOI: 10.3847/0004-6256/152/6/157.
Navarro, J. F., Frenk, C. S., & White, S. D. M. (1997). A Universal Density Profile from Hierarchical Clustering. Astrophysical Journal, 490, 493.
Dutton, A. A., & Macciò, A. V. (2014). Cold dark matter haloes in the Planck era: evolution of structural parameters for NFW haloes. Monthly Notices of the Royal Astronomical Society, 441, 3359–3374.